BACKGROUND AND AIMS
Genome-based antimicrobial susceptibility testing is emerging as a promising alternative to culture-based methods, which remain time-consuming despite being the clinical gold standard.1,2 Here, the authors present an extension of the stacked Random Forest framework, StackPredAMR (under revision), which originally covered 18 antimicrobial agents across three species. At the European Society of Clinical Microbiology and Infectious Diseases (ESCMID) 2026, the authors presented an extension of this framework, demonstrating its straightforward scalability to additional species and antimicrobial agents for multi-agent antimicrobial resistance (AMR) prediction from genomic data.3
METHODS
The model was trained on BVBRC VITEK (bioMérieux, Marcy-l’Étoile, France) antimicrobial susceptibility testing data comprising more than 2,500 isolates from Escherichia coli, Klebsiella pneumoniae, Acinetobacter baumannii, and Enterobacter cloacae, covering up to 23 antimicrobial agents.4 Genomic input features were derived from the Comprehensive Antibiotic Resistance Database (CARD) annotations, and encoded as binary presence/absence of AMR genes.5 The approach builds on the original stackPredAMR architecture by combining individual Random Forest classifiers for each antimicrobial agent with a second-layer meta-model. This stacking strategy enables the model to capture cross-resistance patterns between antimicrobial agents while handling incomplete phenotype labels, a common limitation in AMR datasets.6 Compared to rule-based approaches, which rely on known resistance genes,7 machine learning methods can learn more complex patterns directly from genomic data.8
RESULTS
Model performance was evaluated using 5-fold cross-validation. For E. coli and K. pneumoniae, median major error and very major error rates across antimicrobial agents remained below 3%. Predictions for A. baumannii and E. cloacae, included as a proof of concept with a smaller sample size, were also successfully generated, highlighting the flexibility and extensibility of the framework (Figure 1).
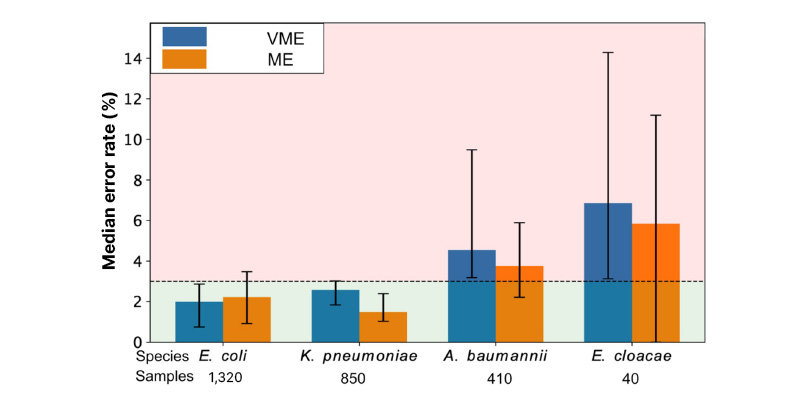
Figure 1: Median error rates and sample counts across antibiotics for four bacterial species.
Median ME and VME rates across antibiotics for four bacterial species, including their sample count. Error bars show 95% bootstrap CIs. The dashed line marks the 3% error threshold.
A. baumannii: Acinetobacter baumannii; E. cloacae: Enterobacter cloacae; E. coli: Escherichia coli; K. pneumoniae: Klebsiella pneumoniae; ME: major error; VME: very major error.
Further analysis of precision–recall performance in relation to effective sample size showed that reduced predictive performance occurred only for antimicrobial agents with limited and imbalanced data. Effective sample size, defined as the harmonic mean of resistant and susceptible isolates, decreased substantially under class imbalance, underlining the importance of sufficiently large and balanced datasets for robust resistance prediction.
CONCLUSION
Overall, this work demonstrates that extending StackPredAMR enables scalable and flexible multi-agent AMR prediction across bacterial species, even in the presence of incomplete phenotype data. Future work will focus on incorporating additional species and antimicrobial agents, integrating regulatory genomic features, and evaluating the approach on metagenomic data to support faster, culture-independent diagnostics.